DeepSeek 开源周六彩蛋-一套组合拳:成本 8.7 万,收入 56 万
2025 年 2 月 24 号-2 月 28 号,DeepSeek 开源了大模型领域的多个关键软件,推动 AGI 向前发展。
你以为这就结束了?今天 (3 月 1 号) DeepSeek 又给出了一份汇总性的内容,总结自己利用这些关键技术,构建自己的推理系统的。
先说结论:
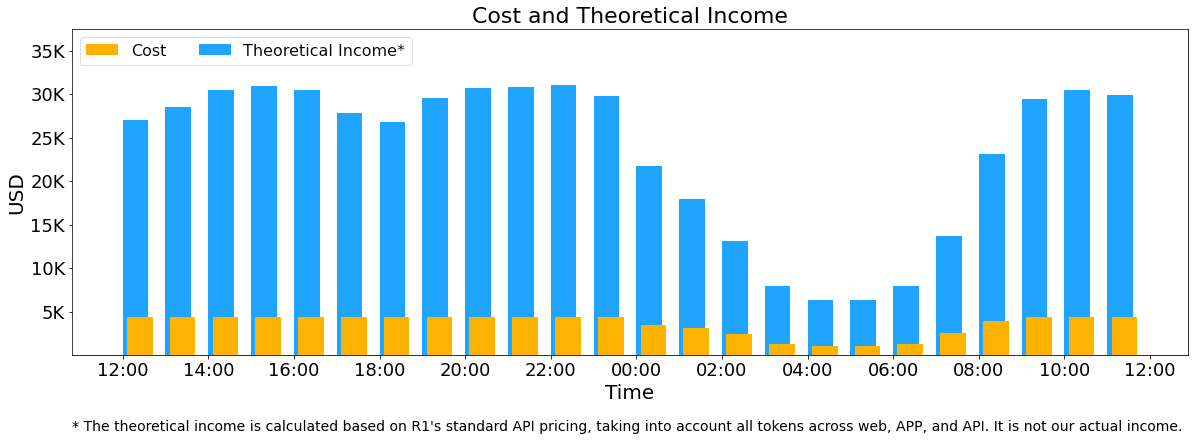
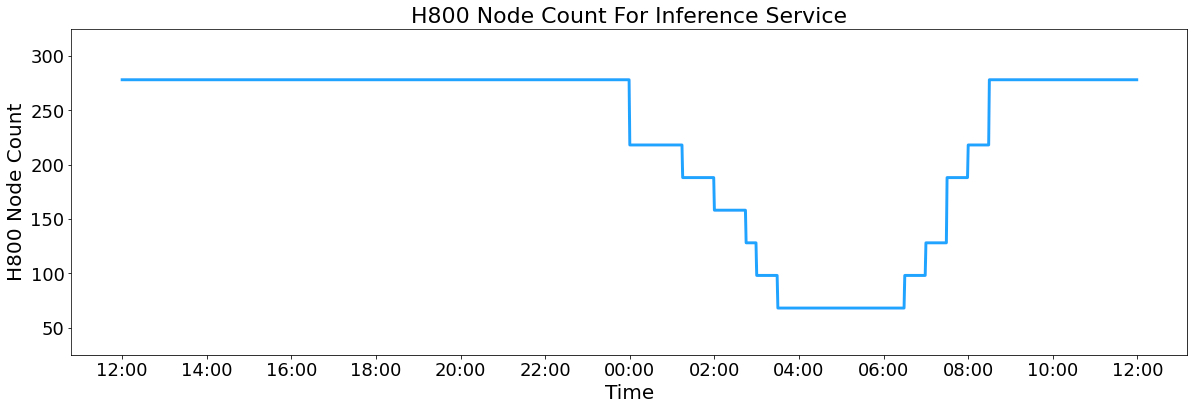
- 平均 1 天使用 226.75 个计算节点 ,每个节点 8 张 H800,假设每块 H800 GPU 的租赁成本为每小时 2 美元,日均成本为 87072 美元。
- 如果所有 token 都按 DeepSeek-R1 价格计算,日均收益将达 562027 美元。
基本上压榨全部的 GPU 资源了。
系统设计原则
DeepSeek-V3/R1 推理系统的设计以下面原则为基础
- 高吞吐量
- 低延迟
- 高可用性
采用的技术
大规模跨节点专家并行(EP)
DeepSeek-R1 推理系统采用了大规模跨节点专家并行技术,通过将模型划分为多个专家子模型并在不同节点上并行处理,显著提升了推理性能。该技术结合了以下关键组件:
- 专家并行计算:每个节点独立运行专家子模型,实现并行化。
- 通信优化:采用高效的通信机制,减少节点之间的数据传输 overhead。开源的 DeepEP
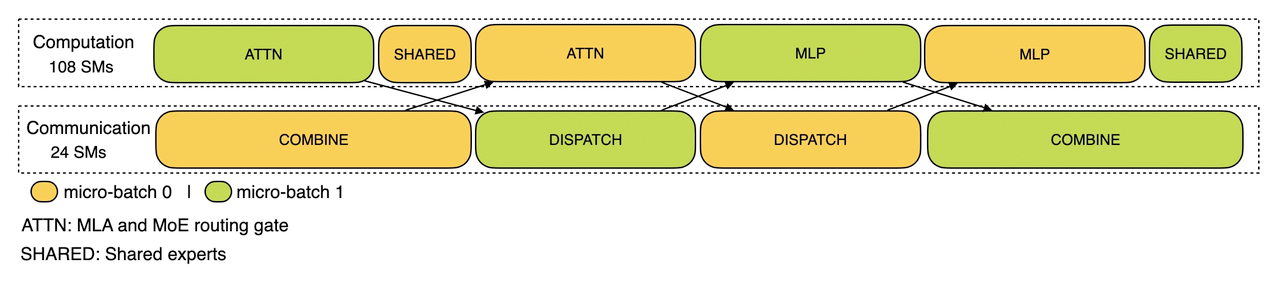
计算与通信重叠
通过在专家并行过程中动态调整数据传输和模型推理的顺序,最大限度地降低了整体处理时间。
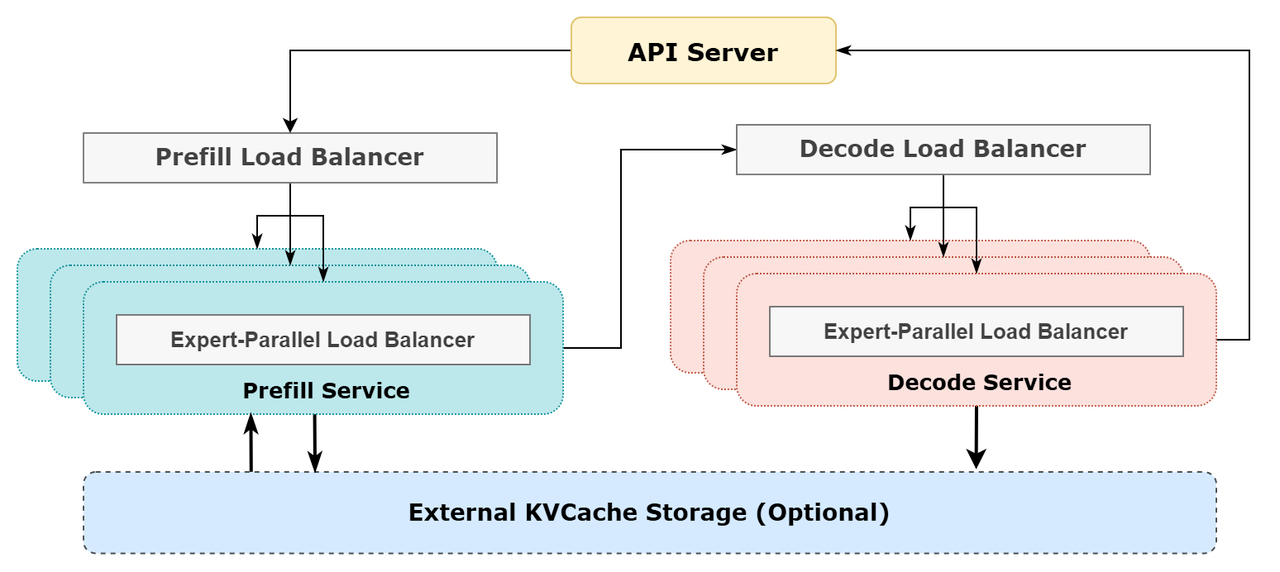
最优负载平衡
为了确保资源的高效利用,DeepSeek-R1 推理系统采用了多层次的负载均衡策略:
- 填充负载均衡器
- 核心注意力计算负载在各 GPU 之间实现平衡(核心注意力计算负载平衡)。
- 等量分配各 GPU 的输入 token 数(派发发送负载平衡),防止特定 GPU 长时间负载过重
- 解码负载均衡器
- KVCache 使用在各 GPU 之间实现平衡(核心注意力计算负载平衡)。
- 等量分配各 GPU 上的请求数(派发发送负载平衡)。
- 专家级并行负载均衡器
- 在每块 GPU 上实现专家计算的负载平衡(即最小化各 GPU 的接收负载最大值)。
收益
以 24 小时为统计周期,DeepSeek-R1 推理服务的表现如下
- 输入 token 数量:总计
608B(6.08 亿),其中342B(3.42 亿 56.3%)通过 KVCache 进行缓存命中。 - 输出 token 数量:总计
168B(1.68 亿)。平均输出速度为每秒 20–22 个 token,平均每个输出 token 的 KVCache 长度为 4989 tokens。 - 节点吞吐量:在预处理阶段(prefilling),单 H800 节点的平均吞吐量约为 73.7 千 token/s;在推理阶段(decoding),平均吞吐量约为 14.8 千 token/s。