
ollama 0.7 发布,新引擎支持多模态模型

qwen3 系列模型发布,深度思考,快速响应
qwen3 概览 分为密集模型架构 (0.6B/1.7B/4B/8B/14B/32B) 和混合专家架构 (30B-A3B/235B-A22B) 混合思维模式:支持开启/关闭推理能力即思考模式和非思考模式,使用户能够根据具体任务控制模型进行思考的
2025 内容精粹
碎言碎语 如何学英语 去网上下载 20 分钟一段的,比如法国国际广播,你一个字一个字查字典,花几天的时间把它听写下来,可能好多好多页。然后呢,你再花 3
Llama4 系列模型发布

要点
- 混合专家架构,原生支持多模态
- 发布
Llama 4 Scout和Llama 4 Maverick两款原生多模态大模型 - 支持 1000 万 Token 上下文,开辟了无限可能,包括多文档总结、解析大量用户活动以执行个性化任务以及在庞大的代码库上进行推理
- Llama 4 Scout 有 17B 活跃参数,配备了 16 位专家,是同类中最好的多模态模型。可以完全嵌入到一个 NVIDIA H100 GPU 中运行
- Llama 4 Maverick 同样有 17B 个活跃参数,
但拥有 128 位专家。它在广泛的基准测试中超越了 GPT-4o 和 Gemini 2.0 Flash,并且在推理能力和编程等任务上与 DeepSeek v3 相比仅需不到一半的活跃参数就能达到相似的表现 - Llama 4 Scout 和 Llama 4 Maverick 都是从 Llama 4 Behemoth 蒸馏而来,Llama 4 Behemoth 有 288B 参数,还在训练中,拥有 16 位专家,是目前最强大的模型之一,在多个 STEM 基准测试上超越了 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro
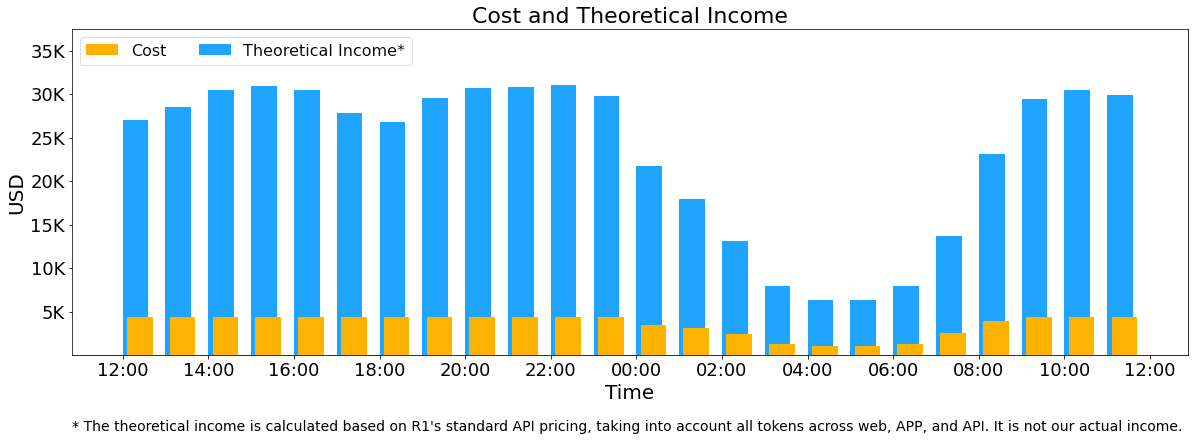
DeepSeek 开源周六彩蛋-一套组合拳:成本 8.7 万,收入 56 万
2025 年 2 月 24 号-2 月 28 号,DeepSeek 开源了大模型领域的多个关键软件,推动 AGI 向前发展。
你以为这就结束了?今天 (3 月 1 号) DeepSeek 又给出了一份汇总性的内容,总结自己利用这些关键技术,构建自己的推理系统的。
先说结论:
- 平均 1 天使用 226.75 个计算节点 ,每个节点 8 张 H800,假设每块 H800 GPU 的租赁成本为每小时 2 美元,日均成本为 87072 美元。
- 如果所有 token 都按 DeepSeek-R1 价格计算,日均收益将达 562027 美元。
基本上压榨全部的 GPU 资源了。
跟着 Deepseek 提示词文档学习使用大模型
在浏览 DeepSeek 官网 API 文档 时,笔者发现了非常有用的资源,那就是 DeepSeek 官方出品的 提示词库 :

2024 年内容精粹
约翰 John 来源 昨天晚上和一位上市公司高管彻夜长谈。他的一席高论震撼了我,也解决了我的一个困惑:为何有的人年纪轻轻就有巨额收入,而且认知和悟性不是
qwen2.5-coder 发布,实测有点用,又好像没用
大陆时间 2024 年 11 月 12 日凌晨 3 点左右,阿里千问团队发布 Qwen2.5-Coder 系列模型

SearXNG 部署和使用

SearXNG 是一个免费的互联网元搜索引擎,它整合了来自超过 70 个搜索服务的结果。用户不会被跟踪或进行特征分析,很好地保护了用户隐私。